Caching in AWS
As cloud computing is becoming a more common way of storing and managing data for all small to large-sized enterprises, the importance of understanding data usage patterns and the distance from the requestor entity has become vastly important. Distance is key to improved response times. Following are the three factors to a quicker response time:
- Where the requested data resides (physically different machines, buildings, zones, regions),
- What kind of storage it uses (SSD, HDD),
- What format the data is stored in (binary, JSON etc).
Caching is a feature that enables you to build applications with sub-second latency, and is key in designing and delivering high-performance distributed applications on the cloud.
1. What is caching
A cache is a high-speed data storage layer that needs to be served faster than is possible by accessing the primary data storage location. With modern architecture styles and patterns, caching definition itself has evolved and data on the cache can be both transient or durable** depending on the use case.
**In-Memory cache layer can also be designed as a standalone data storage layer in contrast to caching layer only from a primary location.
2. Why & When use caching
Numerous use cases can benefit from caching. One fact about data on the cloud is- it is “distributed data.” A simple stab at deciphering the word “Distributed” is — requested data can be on physically different machines, buildings, zones, and even regions. So obvious challenge is bringing together this data from all sources(could be single or multiple) for a given request quickly. Depending upon whether the data is static, dynamic, or frequently accessed, there are different ways of designing and serving this data to benefit from:
- High Performace by serving the frequently accessed and/or pre-processed data requests from the cache rather than gathering it from the actual source or downstream systems like database, 3rd party applications e.t.c.
- Reduce cost by serving more data from the cache, resulting in less traffic to backend application and database, which reduces cost (true for serverless architecture) and also reduces the load on the backend. In simpler words, you can serve more read-heavy traffic with less cost.
3. Where to cache
Let’s look at a frequently used and repeatable serverless design on AWS with and without caching. The below diagram will help in understanding in what layers caching can be applied.

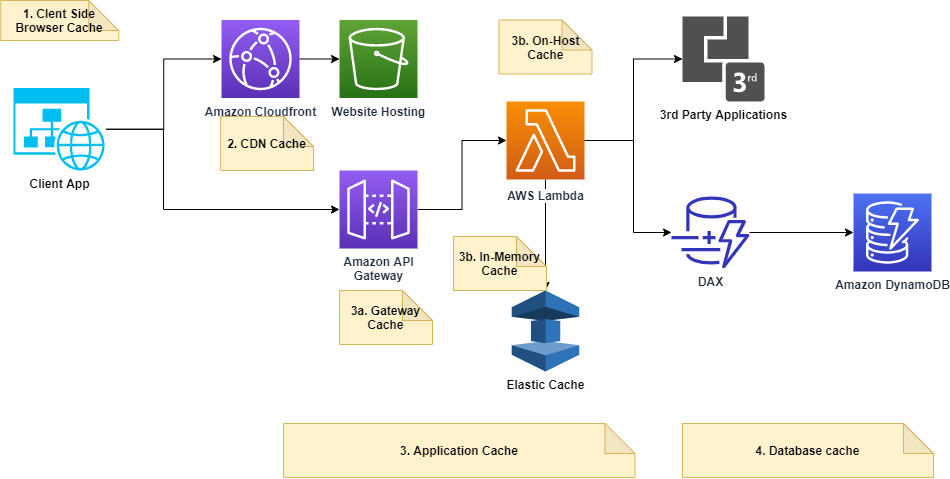
Caching layers / Options in reference to the above diagram
- Client-side cache– This would be caching done at a browser level if using web browser application or local cache of devices (ios/android) for mobile applications.
- CDN cache- The Amazon Cloudfront service is a great option to cache static contents like images, files, videos fronting your s3 buckets (s3 as the origin of cloud front)hosting your websites. With Lambda@Edge compute, the possibilities are endless of what you can serve and secure via your CDN network.
- Application Cache
a. Gateway caching: You can enable API caching in Amazon API Gateway to cache your endpoint’s responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API.
b. On-host caching (Lambda): This is a very powerful option if you have a more customized use case. In the serverless world, lambda would act as an on-host cache. There are a couple of ways you can implement caching with lambdas.
1. The preferred way is by adding lambda extensions to your lambda functions. With this approach, you can create an in-memory, fast and secure cache that caches responses from various back-end services like databases, parameter store, etc, and is refreshed as per the configured TTL(Time to Live). Refer to this article for implementation details.
2. A more traditional approach builds on the fact that any declarations in your Lambda function code (outside the handler code) remain initialized, providing additional optimization when the function is invoked again. So whatever needs to be cached goes outside the handler code. Life cycle management of the cached object needs custom logic to implement TTL.
c. In-Memory caching: AWS Elastic cache (Redis/Memcached)is a fully managed service(but not serverless) that provides you the option of using Redis/Memcache as an external/side cache. It is a popular choice for real-time use cases like Caching, Session Stores, Gaming, Geospatial Services, Real-Time Analytics, and Queuing. - Database cache- Caching response of databases can provide you that additional ultra-low latency. If that is required, then DAX is a purpose-built cache service for dynamodb and is more efficient compared to side cache like ElasticCache.
Conclusion:
Now that you are aware of all the caching tools in your serverless toolbox, let me wrap up with 6 key takeaways:
- Just because you can doesn’t mean you should cache. Premature optimization is the root of all evil.
- You should not cache the same data at multiple layers. Understand and Identify the appropriate caching layer, as per your use case.
- Always apply TTL to your cached items.
- Have a contingency process for forcing a cache refresh on-demand.
- If using an in-memory cache like ElasticCache for data storage (instead of as a traditional cache), agree on RTO(Recovery Time Objective) and RPO(Recovery Point Objective) upfront.
- If using the lambda caching technique (declaration outside the handler code), be aware that each instance of lambda will end up refreshing from the cache at different times(as per the TTL logic implemented). This can lead to inconsistent results at a given point in time, as a call to API gateway can end up either creating a new lambda or reusing an existing warm lambda with its TTL policy. Be mindful to check if this is acceptable for your use case.
With serverless computing and on-demand managed services, don’t be afraid to explore newer options and patterns. I have used ElasticCache for traditional caching, but also as a super quick database. Although this is breaking the traditional mindset of using cache as a transient store only. But with the correct use of cloud-native services, and the ability to recover quickly from a disaster, it is an amazingly lightning-fast and durable way of delivering applications on the cloud.
About Author
Uma Mahesh
Author is working as an Architect in a reputed software company. He is having nearly 17+ Years of experience in web development using Microsoft Technologies.