Choose a Database for Microservices — CAP Theorem
In this article, we are going to discuss How to choose database for Microservices in order to understand data considerations for microservices with learning practices and patterns about Microservices Data Design patterns. And we will use these pattern and practices when designing e-commerce microservice architecture.
By the end of the article, you will learn how to choose database in Microservices Architectures with applying CAP Theorem in Microservices Data Design patterns and principles.
How to Choose a Database for Microservices ?
This really important question and there are several way to understand your database requirements as per microservices.
There are several key points when we decide databases. First of all is the consider the “consistency level” that we need. Do we need Strict consistency or Eventual consistency ? If we are working on banking industry then Strict consistency should use for example debit or withdraw on bank account.
And if we need to Strict consistency, we should select relational databases in order to perform acid in transactional scopes. But mostly if possible we should follow Eventual consistency in microservices architecture in order to gain scalability and high availability.
Another key point is the “high scalability”. If our application need to accommodate millions of request than it should scale fast and easily. But in order to provide this, we should sacrifice strict consistency, because since we distribute the data in different servers, its imposible to make strict consistency due to network partitioning nature.
So another key point could be “high availability”. In order to perform “high availability”, we should separate our data center, split them into different nodes and partitions. But again it results to sacrificing consistency.
So as you can see that we have several key points and they result some benefits and drawbacks when we deciding database in microservices architecture.
For combining all these key points, it becomes CAP Theorem that explains better to this situation. So that means, when we try to decide databases in microservices, we should check the CAP Theorem.
CAP Theorem
Before we Choose a Database for Microservices, we should check the CAP Theorem. The CAP Theorem was found in 1998 by a professor Eric Brewer. This theorem try to prove that in a distributed system, Consistency, Availability, and Partition Tolerance cannot all be achieved at the same time. You can see at the picture, It is usually expressed with this picture.

So according to CAP Theorem, distributed systems should sacrifice between consistency, availability, and partition tolerance. And, any database can only guarantee two of the three concepts; consistency, availability, and partition tolerance.
Now lets start to explain these concepts of CAP Theorem.
Consistency
Consistency means that if the system get any read request, the data should return last updated value from database under all circumstances. If the data cannot be retrieved, an error should be throw and if data is not up-to-date, then it should never be returned. So, when consistent not provide, the system must block the request until all replicas update.
Availability
The ability of a distributed system to respond to requests at any time. If distributed system can respond all request any time, we can say that the system has high availability. Even if one node in any cluster is down, the system should be able to survive with other nodes. Also high available systems can be fault-tolerance in order to accommodate all requests. Availability in a distributed system ensures that the system remains operational 100% of the time.
Partition Tolerance
Partition Tolerance is actually network partitioning. That means, parts of your system are located in different networks. Partition Tolerance is the ability of the system to continue its life in case of any communication problem that may occur between the nodes. Its basically guarantees the system continues to operate even if one data node is down.
Consistency and Availability at the same time ?
So now we should ask this question is it possible for a system to be both Consistency and Availability at the same time?
CAP Theorem said that If there is Partition Tolerance, either Availability or Consistency should be selected. We should sacrifice Availability or Consistency in distributed systems.
In distributed systems, it is a common way that data centers are kept in different locations, mostly on different machines and networks. For this reason, Partition Tolerance is a must for distributed architectures. Because one of the reasons for the emergence of NoSQL databases is to easily overcome the Single Point of Failure problem.
Because in relational databases mostly stored in the data center is in a single network infrastructure that creates a kind of single point of failure situation. Relational databases prevent distribute data from different nodes. For this reason, NoSQL databases don’t include foreign keys, joins, that is, relations between data.
The unrelated data allows it to be stored in a distributed manner much more easily within the different nodes of the system. This also makes NoSQL type databases easily scalable.
As a result, in this case, a distributed system doesn’t have the luxury of not providing Partition Tolerance anyway. When you look at the no-sql database systems like MongoDB, Cassandra, you can see that none of them gave up on Partition Tolerance and made a choice between Availability and Consistency.
So in a distributed architecture, Partition Tolerance seems to be a must-have feature. In this case, it is usually necessary to choose between Consistency or Availability when designing distributed systems.
If a system is to be fully consistent, it must be sacrifice that always available. Otherwise, even if it is desired to be accessible at all times, the consistency should be sacrificed. Mostly in microservices architectures choose Partition Tolerance with High Availability and follow Eventual Consistency for data consistency.
As you can see that how we can consider CAP Theorem when designing distributed systems and understand the concepts of Consistency, Availability, and Partition Tolerance.
Scale Database in Microservices
we are going to talk about Data Partitioning types which’s are Horizontal, vertical, and functional data partitioning.
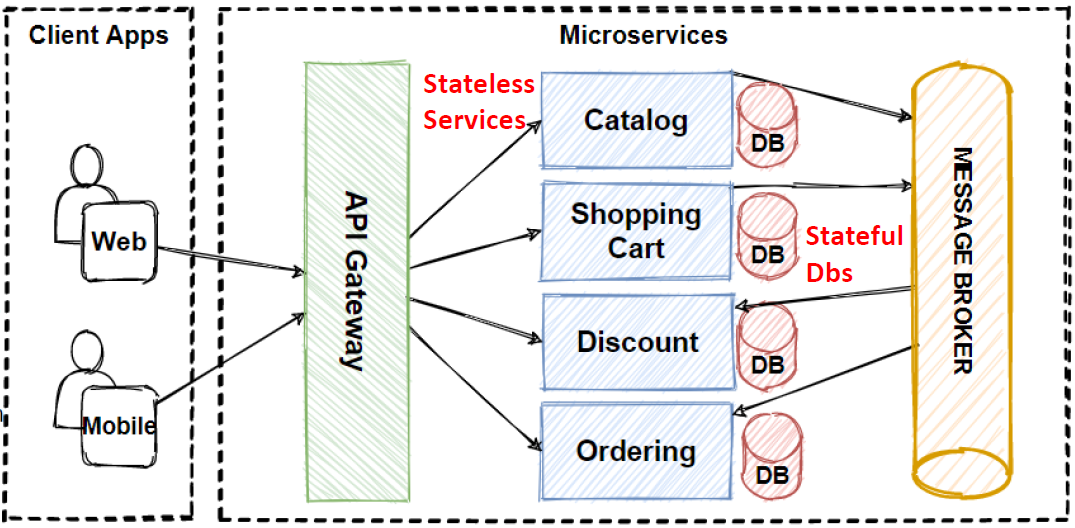
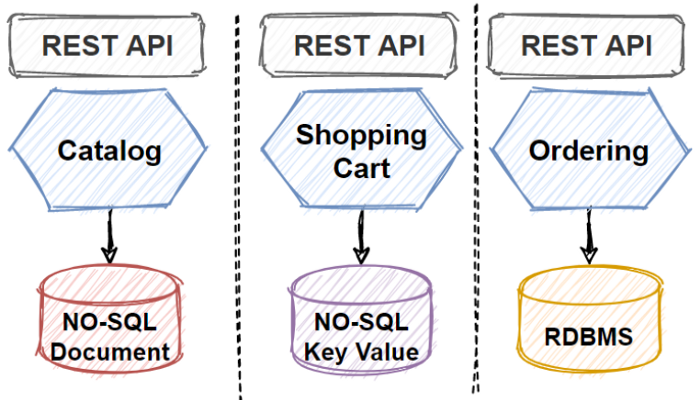
When we are discussing about scaling databases in our microservices architecture, we said that we should split databases in order scale properly for databases.
So we should evolve our architecture with applying other Microservices Data Patterns in order to accommodate business adaptations faster time-to-market and handle larger requests.
About Author
Uma Mahesh
Author is working as an Architect in a reputed software company. He is having nearly 17+ Years of experience in web development using Microsoft Technologies.