Data Consistency in Microservices
Data consistency is hardest part of the microservices architecture. Because in a traditional monolith application, a shared relational database handles data consistency. In a microservices architecture, each microservice has its own data store if you are using database per service pattern. So databases are distributed among the applications. Each application may use different technologies to manage their data like non-sql databases. Although this kind of distributed architecture has many benefits such as scalability, high availability, agility etc., in terms of data management, there are some critical points regarding data such as transaction management and data consistency/integrity.
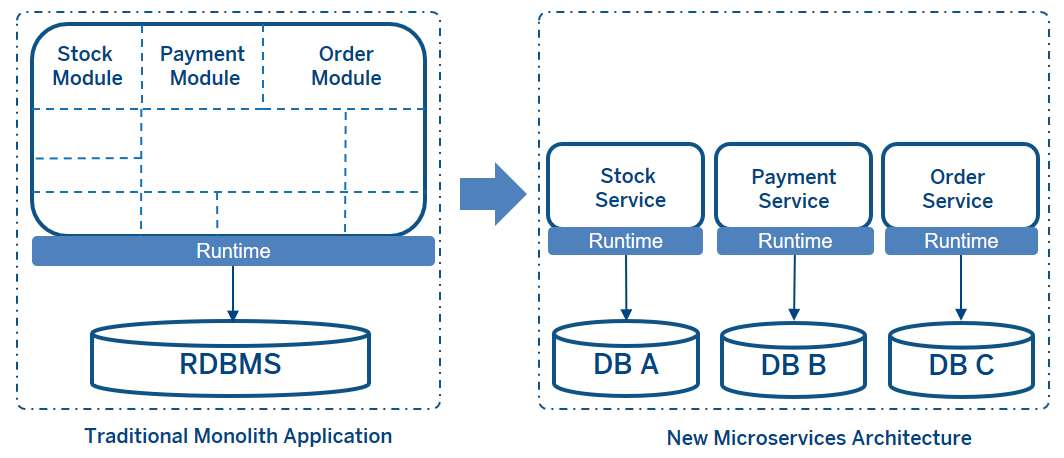
In the distributed architecture, data is highly available and scalable because each microservice has its own runtime and data store.
The Problem: Data Consistency in Distributed Systems
For monolith applications, a shared relational database handles and guarantee data consistency by ACID transactions. The acronym ACID means:
- Atomicity: all the steps of a transaction is succeeded or failed together, no partial state, all or nothing.
- Consistency: all data in the database is consistent at the end of transaction.
- Isolation: only one transaction can touch the data in the same time, other transactions wait until completion of the working transaction.
- Durability: data is persisted in the database at the end of the transaction.
In order to maintain strong data consistency, relational database management systems support ACID properties.
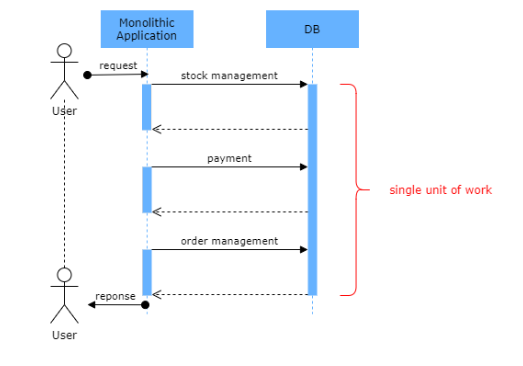
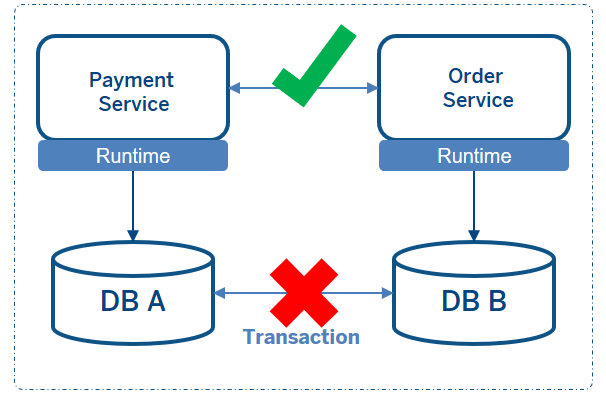
But in a microservices architecture, each microservice has its own data store which has different technologies. So, there is no central database, no single unit of work. Business logic is spanned to the multiple local transactions. This means that you can’t use single transaction unit of work among databases in a microservices architecture. But you still need the ACID properties in your application.
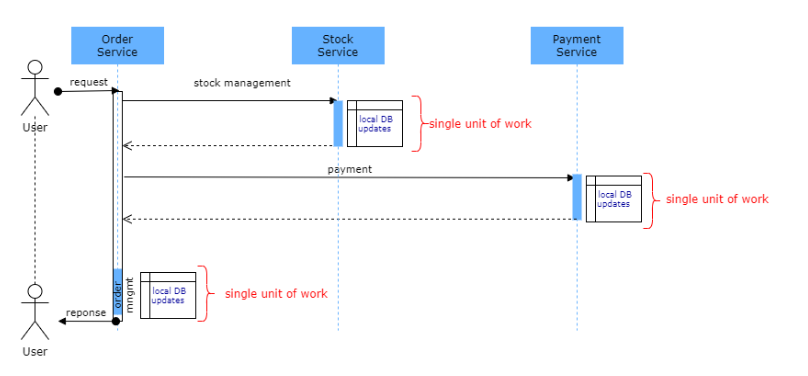
Let’s explain with a simple sample scenario. In an order management system, there might be services such as stock management, payment and order management. Let’s assume that these services are designed in accordance with microservice architecture and database per service pattern is applied. In order to complete the order process, the order service first calls the Stock Management service for stock control and reservation, and the relevant products in the order are reserved for not selling to another customer. The second step is the payment step. Payment service is responsible for the payment business. Order Service calls the Payment Service and completes the payment from the customer’s credit card. Since each one is a separate service, updates over the separated DBs are committed within the service scope. The last step is creating order record. In this step, let’s say a technical error has occurred and the order record could not be created, the order number could not be sent to the customer, but the payment was received from the customer. Data consistency problem occurred here. I will talk about what can be done after this point in the Possible Solutions section in the rest of the article.
Possible Solutions
First of all, there is no single solution which works well for each case. Different solutions can be applied depending on the use-case.
There are two main approaches to solve the problem:
- Distributed transactions
- Eventual consistency
Distributed Transactions
In a distributed transaction, transactions are executed on two or more resources (e.g. databases, message queues). Data integrity is guaranteed across multiple databases by distributed transaction manager or coordinator.
A distributed transaction is a very complex process since multiple resources are involved in the process.
Two-phase commit(2PC) is a blocking protocol used to guarantee that all the transactions are succeeded or failed together in a distributed transaction.
The XA standard is a specification for the 2PC distributed transactions. JTA includes standard API for XA. JTA-compliant application servers support XA out-of-the-box. But all the resources have to be deployed to a single JTA platform to run 2PC. For a microservice architecture, it is not suitable.
Benefits of Distributed Transactions
- Strong data consistency
- Support ACID features
Drawbacks of Distributed Transactions
- Very complex process to maintain
- High latency & low throughput since it is a blocking process (not suitable for high load scenarios)
- Possible deadlocks between transactions
- Transaction coordinator is a single point of failure
Eventual Consistency
Eventual consistency is a model used in distributed systems to achieve high availability. In an eventual consistent system, inconsistencies are allowed for a short time until solving the problem of distributed data.
This model doesn’t apply to distributed ACID transactions across microservices. Eventual consistency uses the BASE database model.
While ACID model is providing a consistent system, BASE model provides high availability.
The acronym BASE means;
- Basically Available: ensures availability of data by replicating it across the nodes of the database cluster
- Soft-state: due to lock of the strong consistency data may change over the time. Consistency responsibility is delegated to the developers.
- Eventual consistency: immediate consistency may not possible with BASE but consistency will be provided eventually (in a short time).
SAGA is a common pattern that operates the eventual consistency model.
The Saga pattern is an asynchronous model, based on a series of services. In a Saga pattern, the distributed transaction is performed by asynchronous local transactions on all related microservices. Each services updates their own data in a local transaction. Saga manages the execution of the sequence of services.
Two most common implementations of Saga transactions are:
Choreography-based SAGA: No central coordinator exists in this case. Each service produces an event after completion of its task and each service listens to events to take an action. This pattern requires an mature event-driven architecture.
- Event Sourcing is an approach to store the state of event changes by using an Event Store. Event Store is a message broker acting as an event database. States are reconstructed by replaying the events from the Event Store.
- Choreography-based SAGA pattern can work well for small number of steps in a transaction (e.g. 2 to 4 steps). When number of steps in a transaction is increasing, it is difficult to track which services listen to which events.
Orchestration-based SAGA: A coordinator service (Saga Execution Orchestrator, SEG) is responsible for sequencing transactions according to business logic. Orchestrator decides to which operation should be performed. If an operation fails, Orchestrator undo the previous steps. It is called as compensation operation. Compensations are the actions to apply when a failure happens to keep the system in consistent state.
- Undoing changes may not be possible already when data has been changed by a different transaction.
- Compensations must be idempotent because they might be called more than once within the retry mechanism.
- Compensations should be designed carefully.
There are some available frameworks to implement the Saga orchestration pattern e.g. Camunda, Apache Camel.
Benefits of SAGA
- Perform non-blocking operations running on local atomic transactions
- Offer no deadlocks between transactions
- Offer no single point of failure
Drawbacks of SAGA
- Eventual data consistency
- Does not have read isolation, needs extra effort (e.g. the user could see the operation being completed, but in a few second, it is cancelled due to a compensation transaction.)
- Difficult to debug, when participant service count is increased
- Increased development cost (actual service developments plus compensations service developments are required)
- Design is complex
Data consistency between the distributed data stores can be extremely difficult to maintain. There needs to be a different mindset in design of the new applications.
We can say that responsibility for data consistency moves from database to application level.
Which Solution to Choose
The solution depends on the use case and consistency requirements.
In general, the following design considerations should be taken into account.
- Avoid using distributed transactions across microservices if possible. Working with distributed transactions brings more complex problems.
- Design your system that doesn’t require distributed consistency as much as possible. To achieve this, identify transaction boundaries as following;
- Identify the operations that have to work in same unit of work. Use strong consistency for this type of operations
- Identify the operations that can able to tolerate possible latencies in terms of consistency. Use eventual consistency for this type of operations
3. Consider using event-driven architecture for asynchronous non-blocking service calls
4. Design fault-tolerant systems by compensations and reconciliation processes to keep the system consistent
5. Eventual consistent patterns requires a change in mindset for design and development
Conclusion
Microservices architecture has great features such as high availability, scalability, automation, autonomous teams etc. A number of changes in traditional methods are required to obtain maximum efficiency of the microservice architectural style. Data and consistency management is one of the topics that needs to be designed carefully.
About Author
Uma Mahesh
Author is working as an Architect in a reputed software company. He is having nearly 17+ Years of experience in web development using Microsoft Technologies.