Scaling Software Architectures
We live in an age where massive scale, Internet-facing systems like Google, Amazon, Facebook and the like are engineering icons. They handle vast volumes of requests every second and manage data repositories of unprecedented size. Getting precise traffic numbers on these systems is not easy for commercial-in-confidence reasons. Still, the ability of these sites to rapidly scale as usage grows is the defining quality attribute behind their ongoing success.
For the vast majority of business and Government systems, scalability is not a primary quality requirement in the early stages of development and deployment. New features to enhance usability and utility are drivers of our development cycles. As long as performance is adequate under normal loads, we keep adding user-facing features to enhance the system’s business value.
Still, it’s not uncommon for systems to evolve into a state where enhanced performance and scalability become a matter of urgency or even survival. Attractive features and high utility breed success, which brings more requests to handle and more data to manage. This often heralds a tipping point, where design decisions that made sense under light loads are now suddenly technical debt. External trigger events often cause these tipping points — look in the March 2020 media at the many reports of Government Unemployment and supermarket online ordering sites crashing under demand caused by the coronavirus pandemic.
When this tipping point is reached, it’s the responsibility of architects to lead the system evolution towards a highly responsive, scalable system. Core system architectural mechanisms and patterns will need re-engineering to make it possible to handle the increased demand. For many architects, this is unknown or unfamiliar territory, as scalability leads us down paths that are sometimes heretical to widely understood software architecture principles.
The following six rules of thumb represent knowledge that every software architect should have to aid them in building a scalable system. These general rules can act as guidance for architects on their journey towards reliably handling ever-growing request loads and data volumes.
Cost and scalability are indelibly linked
A core principle of scaling a system is being able to easily add new processing resources to handle the increased load. For many systems, a simple and effective approach is deploying multiple instances of stateless server resources and using a load balancer to distribute the requests across these instances (see Figure 1). Assuming these resources are deployed on a cloud platform such as Amazon Web Services, your basic costs are:
- Cost of the virtual machine deployments for each server instance
- Cost of the load balancer, determined by the number of new and active requests, and data volumes processed
In this scenario, as your request load grows, you will need to have more processing capacity in terms of deployed virtual machines running your server code. This incurs higher costs. Your load balancer costs will also grow proportionally to your request load and data size.

Hence cost and scale go together. Your design decisions for scalability inevitably affect your deployment costs. Forget this and you might findyourself, along with many prominent companies, receiving unexpectedly large deployment bills at the end of a month!
In this scenario, how can your design reduce costs? There are two main ways:
- Use an elastic load balancer that adjusts the number of server instances based on the instantaneous request load. Then, during light traffic periods, you pay for the minimum number of server instances. As request volumes grow, the load balancer spawns new instances and your capacity grows accordingly.
- Increase the capacity of each server instance. This is typically done by tuning the server deployment parameters (e.g. number of threads, connections, heap size, etc). Default platform settings are rarely optimal for your workload. Carefully choosing parameter settings can see serious performance improvements and hence capacity increases. You are basically doing more work with the same resources — a key tenet of achieving scaling.
Your system has a bottleneck. Somewhere!
Scaling a system essentially means increasing its capacity. In the above example, we increase request processing capacity by deploying more server instances on load-balanced compute resources. However, software systems comprise multiple dependent processing elements, or microservices. Inevitably, as you grow capacity in some microservices, you swamp capacity in others.
In our load-balanced example, let’s assume our server instances all have connections to the same shared database. As we grow the number of deployed servers, we increase the request load on our database (see Figure 2). At some stage, this database will reach saturation, and database accesses will start to incur more latency. Now your database is a bottleneck — it’s doesn’t matter if you add more server processing capacity. To scale further, the solution is to somehow increase your database capacity. You can try to optimize your queries, or add more CPUs and/or memory. Maybe replicate and/or shard your database. There are many possibilities.
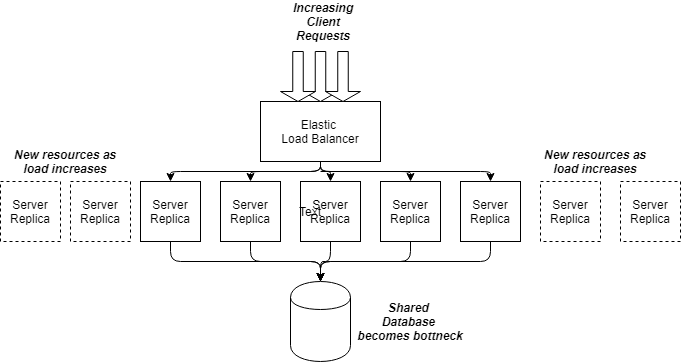
Any shared resource in your system is potentially a bottleneck that will limit capacity. As you increase capacity in parts of your architecture, you will need to look carefully at downstream capacity to make sure you don’t suddenly and unexpectedly overwhelm your system with requests. This can rapidly cause a cascading failure (see next rule) and bring your whole system crashing down.
Databases, message queues, long latency network connections, thread and connection pools and shared microservices are all prime candidates for bottlenecks. You can be assured that high traffic loads will quickly expose these elements. The key is to guard against sudden crashes when bottlenecks are exposed and be able to quickly deploy more capacity.
Slow services are more evil than failed services
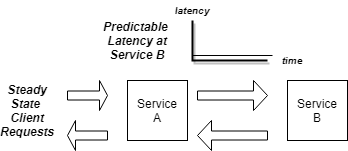
Under normal operations, systems should be designed to provide stable, low latencies for communications between the microservices and databases that comprise a system. While your system load stays within the operational profile you have designed for, performance remains predictable and consistent and fast, as shown below.
As client load increases beyond operational profiles, request latencies between microservices will start to increase. At first, this is often a slow but steady increase that may not seriously affect overall system operations, especially if load surges are shortlived. However, if the incoming request load continues to exceed capacity (Service B), outstanding requests will begin to back up in the requesting microservice (Service A), which is now seeing more incoming requests than completed ones due to slow downstream latencies.
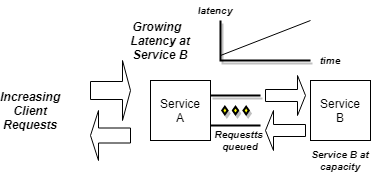
In such situations, things can go south really quickly. When one service is overwhelmed and essentially stalls due to thrashing or resource exhaustion, requesting services become unresponsive to their clients, who also become stalled. The resulting effect is known as a cascading failure — a slow microservice causes requests to build up along the request processing path until suddenly the whole system fails.
This is why slow services are evil, much more so than an unavailable service. If you make a call to a service that has failed or one which is partitioned due to a transient network problem, you receive an exception immediately and can decide what to sensibly do (e.g. backoff and retry, report an error). Gradually overwhelmed services behave correctly, just with longer latencies. This exposes potential bottlenecks in all dependent services, and eventually, something goes horribly wrong.
Architecture patterns like Circuit Breakers and Bulkheads are safeguards against cascading failures. Circuit breakers enable request loads to be throttled or shed if latencies to a service exceed a specified value. Bulkheads protect a complete microservice from failing if only one of its downstream dependencies fails. Use these to build resilient as well as highly scalable architectures.
The data tier is the hardest to scale
Databases lie at the heart of virtually every system. These typically comprise ‘source of truth’ transactional databases, which hold the core data your business needs to function correctly, and operational data sources that contain transient items to feed data warehouses.
Core business data examples are customer profiles, transactions and account balances. These need to be correct, consistent and available.
Operational data examples are user session lengths, visitors per hour and page view counts. This data typically has a shelf life and can be aggregated and summarized over time. It’s also not the end of the world if it’s not 100% complete. For this reason, we can more easily capture and store operational data out-of-band, for example writing it to a log file or message queue. Consumers then periodically retrieve the data and write it to a data store.
As your system’s request processing layer scales, more load is placed on shared transactional databases. These can rapidly become a bottleneck as the query load grows. Query optimization is a useful first step, as is adding more memory to enable the database engine to cache indexes and table data. Eventually though, your database engine will run out of steam and more radical changes are needed.
The first thing to note is that any data organization changes are potentially painful in the data tier. If you change a schema in a relational database, you probably have to run scripts to reload your data to match the new schema. For the period the script runs, which may be a long time for a large database, your system is not available for writes. This might not make your customers happy.
NoSQL, schemaless databases alleviate the need for reloading the databases, but you still have to change your query-level code to be cognizant of the modified data organization. You may also need to manage data object versioning if you have business data collections in which some items have modified formats, and some the original.
Scaling further will probably require the database to be distributed. Perhaps a leader-follower model with read-only replicas is sufficient. With most databases, this is straightforward to set up, but requires close ongoing monitoring. Failover, when the leader dies, is rarely instantaneous and sometimes needs manual intervention. These issues are all very database-engine dependent.
If you adopt a leaderless approach, you have to decide how best to distribute and partition your data across multiple nodes. In most databases, once you have chosen the partition key, it is not possible to change without rebuilding the database. Needless to say, the partition key needs to be chosen wisely! The partition key also controls how data is distributed across your nodes. As nodes are added to give more capacity, rebalancing needs to take place to spread data and requests across the new nodes. Again, how this works is described in the guts of your database documentation. Sometimes it is not as smooth as it could be.
Due to the potential administrative headaches of distributed databases, managed cloud-based alternatives (e.g. AWS Dynamodb, Google Firestore) are often a favored choice. Of course, there are trade-offs involved — that is the subject of another story!
The message here is simple. Changing your logical and physical data model to scale your query processing capability is rarely a smooth and simple process. It’s one to want to confront as infrequently as possible.
Cache! Cache! And Cache Some More!
One way to reduce the load on your database is to avoid accessing it whenever possible. This is where caching comes in. Your friendly database engine should be able to utilize as much on node cache as you care to give it. This is a simple and useful, if potentially expensive, solution.
Better, why query the database if you don’t need to? For data that is frequently read and changes rarely, your processing logic can be modified to first check a distributed cache, such as a memcached server. This requires a remote call, but if the data you need is in cache, on a fast network this is far less expensive than querying the database instance.
Introducing a caching layer requires your processing logic to be modified to check for cached data. If what you want is not in the cache, your code must still query the database and then load the results in the cache as well as return it to the caller. You also need to decide when to remove or invalidate cached results — this depends on your application’s tolerance to serving stale results to clients.
A well designed caching scheme can be absolutely invaluable in scaling a system. If you can handle a large percentage of read requests from your cache, then you buy extra capacity at your databases as they are not involved in handling most requests. This means you avoid complex and painful data tier modifications (see previous rule) while creating capacity for more and more requests. This is a recipe to make everybody happy! Even accountants.
Monitoring is fundamental for scalable systems
One of the issues all teams face as they experience greater workloads is testing at scale. Realistic load testing is simply hard to do. Imagine you want to test an existing deployment to see if it can still provide fast response times if the database size grows by 10x. You first need to generate a lot of data, which ideally echoes the characteristics of your data set and relationships. You need to also generate a realistic workload. For reads, or both reads and writes? You then need to load and deploy your data set and run load tests, probably using a load testing tool.
This is a lot of work. And it is hard to get everything representative of reality so you get meaningful results. Not surprisingly, it is rarely done.
The alternative is monitoring. Simple monitoring of your system involves making sure your infrastructure is operational. If a resource is running low, such as memory or disk space, or remote calls are failing, you should be alerted so that remedial actions can be taken before really bad things happen.
The above monitoring insights are necessary but insufficient. As your system scales, you need to understand the relationships between application behaviors. A simple example is how your database writes perform as the volume of concurrent write requests grows. You also want to know when a circuit breaker trips in a microservice due to increasing downstream latencies, when a load balancer starts spawning new instances, or messages are remaining in a queue for longer than a specified threshold.
There is a myriad of solutions available for monitoring. Splunk is a comprehensive and powerful log aggregation framework. Any cloud has its own monitoring framework, such as AWS Cloudwatch. These allow you to capture metrics about your system’s behavior and present these in a unified dashboard to support both monitoring and analysis of your performance. The term observability is often used to encompass the whole process of monitoring and performance analysis.
There are two things (at least!) to consider.
First, to gain deep insights into performance, you will need to generate custom metrics that relate to the specifics of your application’s behavior. Carefully design these metrics and add code in your microservices to inject them into your monitoring framework so they can be observed and analyzed in your system dashboard.
Second, monitoring is a necessary function (and cost) in your system. It is turned on. Always. When you need to tune performance and scale your system, the data you capture guides your experiments and efforts. Being data-driven in your system evolution helps ensure you invest your time modifying and improving the parts of your system that are fundamental to supporting your performance and scaling requirements.
Conclusions
High performance and scalability are often not the priority quality requirements for many of the systems we build. Understanding, implementing and evolving the functional requirements is usually sufficiently problematic to consume all available time and budget. But sometimes, driven by external events or unexpected success, scalability becomes necessary, otherwise your system is unavailable as it has crashed under the load. And unavailable systems (or effectively unavailable due to slow performance) are of no use to anyone.
Like any complex software architecture, there’s no cookbook or recipes to follow. Trade-offs and compromises are essential to achieve scalability, guided by your precise system requirements. Bear the above rules in mind and the road to scalability should be littered with less unexpected bumps and potholes!
About Author
Uma Mahesh
Author is working as an Architect in a reputed software company. He is having nearly 17+ Years of experience in web development using Microsoft Technologies.